人物介紹: 修經理
目前在營銷部門工作,外型帥氣身材一米八,常獲得女同事的青睞,有時一到辦公室就發現桌上出現愛心早餐,但因為腸胃不好,所以只好將食物分送給部門的其他同仁。為了讓新開發的藥品能在第一時間推出就大受歡迎,常常加班調整展銷策略而睡在公司,因此在公司有「守夜者」的綽號。
2-9 安眠藥客群的設定
「飛先生,好久不見啦!上次托您的福,我的腸胃近期改善許多了,除了服藥之外,最近偶爾也會打打太極來調息氣場。」修經理笑著說道。
「那就好,想到之前你三天兩頭跑廁所也是挺為你擔心的啊。對了,今天有甚麼需要幫你分析的嗎?」飛哥詢問道。
修經理嘆了口氣說著:「你也知道公司最近在開發新藥,所以想利用包含之前市調的時候所收集的資料,請你分析下哪些人可能對於我們的產品比較有興趣。」
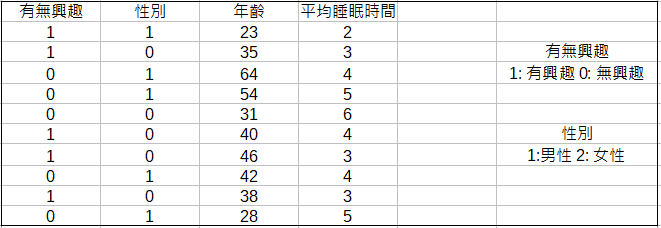
「原來如此,有興趣則以1表示,沒有則以0表示。你可以看到跑完羅吉斯回歸後的模型長這樣,
是否有興趣=exp(0.64+(-0.767)x性別+(0.039)x年齡+(-0.549)x平均睡眠時間)
但是年齡在這個回歸中並不顯著(P-value < 0.05),所以我建議將它拿掉,因此模型變成
是否有興趣=exp(0.885+(-0.647)x性別+(-0.24)x平均睡眠時間)
當你拿掉一個變數後,係數的變動是很正常的,因為其他變數必須試著去解釋「被拿掉的係數」原本解釋的部分,但也有可能沒辦法完整解釋,因此拿掉一個變數可能是好是壞,必須再藉由其他的方式進行判定。另外,我們可以注意到的是
」飛哥仔細的說明著。
修經理眉頭一皺說道:「哦? 跟我預期的有些不太一樣呢?年齡不重要是否代表各個年齡層都有這樣的需求呢?這部分我需要再確認下呢!倒是女性的需求較高符合本公司的預期,這次的分析到挺有趣的,有甚麼其他還需要注意的是像嗎?飛先生。」
「我個人建議不如再多收集些市調的資料吧!畢竟10筆資料而已,不太適合將這麼少數的人套用到大眾呢!或許資料一堆可以找到新的重要客群,也可以多增加幾個問題,比如說職業、身高體重、日夜班等等,增加資料的多樣性。」飛哥提出了一些建議。
「好的,我這就去處理下一批的市調,飛先生感謝你的協助啊!」修經理禮貌的點了點頭,將門闔上後就信步走回辦公室了。
飛哥心想:「就剩下一個啦!不知有甚麼問題,希望有趣些呢!」
Python程式時間
import pandas as pd
import numpy as np
from sklearn import preprocessing
from sklearn.feature_selection import f_regression
data = {'Interested or not?': [1,1,0,0,0,1,1,0,1,0],
'Gender': [1,0,1,1,0,0,0,1,0,1],
'Age': [23,35,64,54,31,40,46,42,38,28],
'Sleeping time': [2,3,4,5,6,4,3,4,3,5]
}
df = pd.DataFrame (data, columns = ['Interested or not?','Gender','Age','Sleeping time'])
y=df['Interested or not?']
x=df[['Gender','Age','Sleeping time']]
# 建立模型
logistic_regr = linear_model.LogisticRegression()
logistic_regr.fit(x, y)
# 印出係數
print(logistic_regr.coef_)
# 印出截距
print(logistic_regr.intercept_ )
# 印出p-value
print(f_regression(x, y)[1])
後記: 大家是否好奇p-value何時算顯著何時算不顯著呢? 下個故事將告訴各位如何選擇適當的p-value,敬請期待。
資料參考:
https://ithelp.ithome.com.tw/articles/10187047
https://researcher20.com/2010/06/02/%E8%A7%A3%E8%AE%80-logistic-regression/


 iThome鐵人賽
iThome鐵人賽